sql连接和groupBy
分清楚内连接、外连接(左(外)连接、右(外)连接)
前提
建表语句
1 | |
1 | |
表测试的两个数据
a_table
| a_id | a_name | a_part |
|---|---|---|
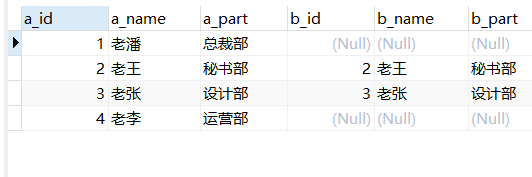
| 1 | 老潘 | 总裁部 |
| 2 | 老王 | 秘书部 |
| 3 | 老张 | 设计部 |
| 4 | 老李 | 运营部 |
b_table
| b_id | b_name | b_part |
|---|---|---|
| 2 | 老王 | 秘书部 |
| 3 | 老张 | 设计部 |
| 5 | 老刘 | 人事部 |
| 6 | 老黄 | 生产部 |
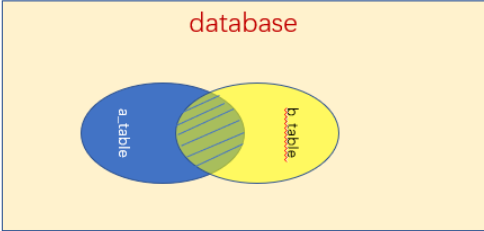
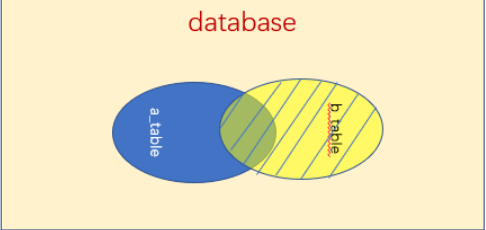
1、内连接
关键字:inner join on或者inner join where
语句
1 | |
执行的结果

说明组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集部分
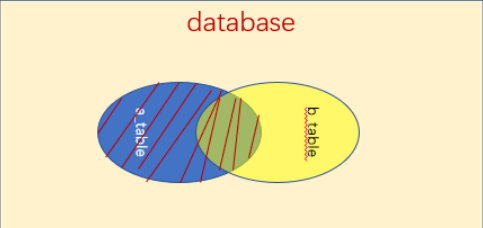
2、左连接(左外连接)
关键字:left join on / left outer join on
语句
1 | |
执行的结果
left join on是left outer join on的一种缩写,它的全称是左外连接,是外连接的一种
左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为null。
3、右连接(右外连接)
关键字:right join on / right outer join on
语句:
1 | |
执行的结果:
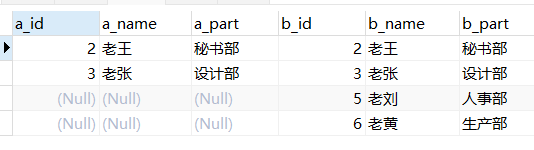
right join on是right outer join on的一种缩写,它的全称是左外连接,是外连接的一种
右(外)连接,右表(b_table)的记录将会全部表示出来,而左表(a_table)只会显示符合搜索条件的记录。左表记录不足的地方均为null。
1 | |
1、groupBy
前提:建表语句
1 | |
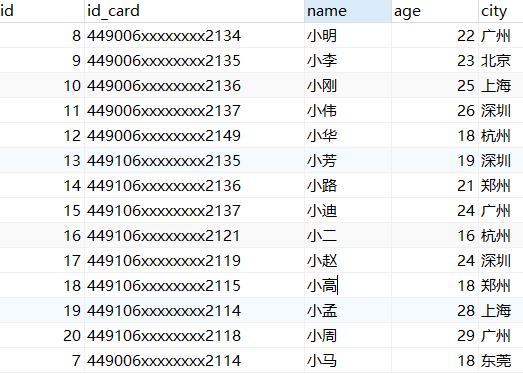
1、统计每一个城市员工的数量
1 | |
as num将新的城市员工的数量这一列的索引置为num
分析一下底层的执行流程
2、group By原理分析
2.1、explain分析

- extra这个字段的
Using temporary表示在执行分组的时候使用了临时表。
创建内存临时表,表中具有两个字段,city和num。
全表扫描stuff的记录,依次取出city = ‘X’的记录。
- 判断临时表中具有city = ‘X’的行,没有就插入一个记录(x, 1);
- 如果临时表中具有city = ‘X’的 行的行,就是将x这一行的num + 1;
3、where 和 having的区别
- group by + where 的执行流程
- group by + having的执行流程
- 同时有where、group by、having的执行顺序
3.1、group by + where的执行流程
2、筛选出年龄大于19岁的员工,并按城市分组,统计每个城市的员工数量,最后按员工数量升序排列
1 | |
执行流程如下:
- 创建内存临时表,表里有两个字段city和num;
- 扫描索引树idx_age,找到大于年龄大于30的主键ID
- 通过主键ID,回表找到city = ‘X’
- 判断临时表中是否有为 city=’X’的行,没有就插入一个记录 (X,1);
- 如果临时表中有city=’X’的行的行,就将x 这一行的num值加 1;
- 继续重复2,3步骤,找到所有满足条件的数据,
- 最后根据字段city做排序,得到结果集返回给客户端。
3.2、group by + having的执行流程
3、查询每个城市的员工数量,获取到员工数量不低于3的城市,having可以很好解决你的问题
1 | |
3.3、同时有where、group by、having的执行顺序
4、筛选出年龄大于19岁的员工,并按城市分组,统计每个城市的员工数量,选出员工数量大于3的城市
1 | |
3.4、Having和where的区别
- having子句用于分组后的筛选,where子句用于行条件筛选
- having一般都是配合group by和聚合函数一起出现的如(count(),sum(),avg(),max(),min())
- where条件子句中不能使用聚合函数,而having子句就可以
- having只能放在group之后,where执行在group by之前
1050. 合作过至少三次的演员和导演 - 力扣(LeetCode)
1 | |
这个题目中,如果用select actor_id, director_id, count(timestamp) as num会更好理解一些